

前回に引き続き
製造プロセスの最適化における「平均処理効果(ATE)」の推定手法について解説します。
前回のブログで述べたように、製造プロセスには多くの要素が複雑に絡み合っているため、一つずつ手動で最適な条件を探るのは大変な作業です。
そこで今回は、マッチングによる効果検証、IPTW法、DR法といった、ATE推定に役立つ手法を製造プロセス(パン製造)の例を使って解説していきます。



効果検証のための3手法
製造プロセスでは複雑な事象が絡み合い、何が原因で結果変数に影響を与えているのかわからない場合が多いです。
パン製造においても、原料の選択、発酵条件、焼成時間や温度など、さまざまな要素が複雑に絡み合っており、それらが最終のパン製品の品質に影響を推定するのが難しくなっています。
これらの要素を個別に調整して最適な条件を見つけても良いですが、非常に時間がかかる作業になるため、工程改善の時間軸と合わないことが容易に想像できます。
本事例では、「発酵の有無(Fermentation)」を原因変数、「パンの形状品質(Shape Quality)」を結果変数として設定しています。さらに、「室温(room_temp_cat)」と「オーブンの保守状況(oven_condition)」を交絡因子として考慮して考えることにします。
今回は、以下の3つの手法を使って、発酵処理が形状品質にどのような平均的な効果を及ぼしているかを明らかにしていこうと思いま。。
- マッチングによる効果検証
- IPTW法によるATE推定
- DR法によるATE推定
マッチングによる効果検証
発酵有りグループと発酵無しグループの中で、室温とオーブンの状況が同等のサンプルを抽出・比較することで、発酵の効果を評価します。これにより、他の要因の影響を排除した状態で、発酵処理が形状品質にどのような影響を及ぼしたかを明らかにできます。
IPTW法
各サンプルの「発酵を受ける確率(propensity score)」を推定し、その逆数を重みとして使うことで、発酵有りグループと発酵無しグループの平均的な形状品質の差(ATE)を求めます。この手法では、観測された交絡因子の影響を統計的に調整することができます。
DR法
マッチングとIPTW法を組み合わせた手法です。まず結果変数である形状品質を説明する回帰モデルを作り、その予測値とIPTW法での重みを用いて、より精度の高いATE推定を行います。
これらの手法を活用することで、発酵処理が形状品質にどのような平均的な効果を及ぼしているかを、交絡因子の影響を排除した状態で明らかにできます。この知見は、製造プロセスの最適化や品質管理、新製品開発などの場面で活用できると期待されています。


傾向スコアマッチング法とは何ですか?
マッチングによる効果検証は、同じ条件下で異なる処理を受けた2つのグループを比較することで、処理の効果を評価する手法です。本事例では、発酵の有無が異なる処理に該当します。
具体的な流れは以下の通りです。
まず、発酵有りグループ(treated)と発酵無しグループ(control)に分けます。
次に、NearestNeighborsアルゴリズムを使ってマッチングを行います。
NearestNeighborsアルゴリズムは、高次元空間における最近傍探索アルゴリズムの1つで、ここでは「室温条件」と「オーブン状況」の2つの変数から成る特徴空間において、control グループから treated グループと同等の条件のサンプルを見つけ出します。
※補足
「室温条件」と「オーブン状況」の2つの変数から成る特徴空間において、treated サンプルと最も近い距離にあるcontrol サンプルをマッチングさせているということ
最後に、マッチングした発酵無しグループの形状品質の平均と、発酵有りグループの形状品質の平均を比較することで、発酵処理の効果を評価します。
この平均値の差が、発酵処理が形状品質に及ぼす影響、つまり平均処理効果(ATE)を示します。
# マッチングによる効果検証
from sklearn.neighbors import NearestNeighbors
# 発酵したグループとしなかったグループに分ける
treated = data[data['fermentation'] == 1]
control = data[data['fermentation'] == 0]
# NearestNeighborsを用いてマッチング
nbrs = NearestNeighbors(n_neighbors=1, algorithm='ball_tree').fit(control[['room_temp_cat', 'oven_condition']])
distances, indices = nbrs.kneighbors(treated[['room_temp_cat', 'oven_condition']])
# マッチングしたデータを取得
matched = control.iloc[indices.flatten()]
# 効果の比較
effect = treated['shape_quality'].mean() - matched['shape_quality'].mean()
print(f'Effect of fermentation on shape quality: {effect}')Effect of fermentation on shape quality: 3.3385166610823376このマッチング法は手法が直感的であり、結果を視覚化して比較しやすい特徴があります。発酵を行ったグループと行わなかったグループのパンの形状品質を比較する箱ひげ図を作成しました。
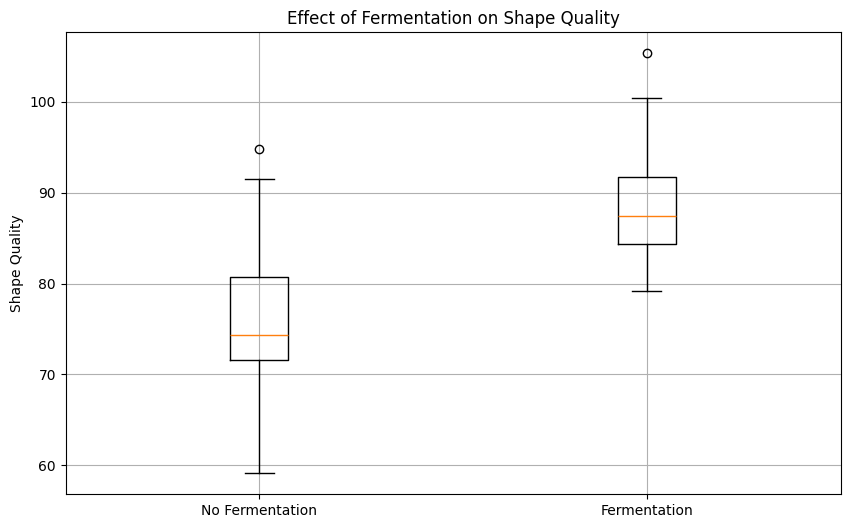
Effect of fermentation on shape qualityは、発酵を行ったグループと行わなかったグループのパンの形状品質の平均の差を表しています。この値は、箱ひげ図上では、’Fermentation’の箱の中央の線(中央値)と’No Fermentation’の箱の中央の線(中央値)の差として視覚的に理解することができます。

IPTW法を分かりやすく解説
IPTW法は、処理を受けるかどうかの「傾向スコア」を使って、各サンプルの重みを調整することで、平均処理効果(ATE)を推定する手法です。傾向スコアとは、観測された共変量を考慮した上で、ある処理を受ける確率のことを指します。
本事例では、発酵の有無が処理に当たり、「室温条件」と「オーブン状況」が共変量となります。まずはこれらの共変量から、各サンプルの「発酵を受ける確率」を推定します。
次に、発酵有りグループのサンプルについては、その逆数の値を重みとして使います。一方、発酵無しグループのサンプルについては重みを1として扱います。
そして、この重み付けされた treated グループの形状品質の平均と、control グループの形状品質の平均の差を取ることで、発酵処理のATE を推定しています。
最後に、この重み付けされた形状品質の平均値の差から、発酵処理が形状品質に及ぼすATEを推定します。
# IPTW法によるATE推定
weights = treated['propensity_score'] / (1 - treated['propensity_score'])
ate_iptw = (treated['shape_quality'] * weights).sum() / weights.sum() - control['shape_quality'].mean()
print(f'ATE by IPTW: {ate_iptw}')ATE by IPTW: 12.366317520742001
DR推定量とは何ですか?
DR法は、マッチングとIPTW法を組み合わせた手法です。
マッチングでは、処理グループと非処理グループの間で、観測された共変量の分布を近づけることができます。
一方、IPTW法では、各サンプルに重みを付与することで、共変量の影響を統計的に調整することができます。
DR法は、これらの2つの手法のメリットを組み合わせた手法です。
具体的には、まず処理グループの形状品質を説明する回帰モデルを作成します。そして、この回帰モデルの予測値と、IPTW法で求めた重みを組み合わせて、最終的なATE推定量を算出します。
この手法により、マッチングとIPTW法それぞれの長所を生かすことができ、より精度の高いATE推定が可能になります。
以下にPythonによるDR法のコード例を示します。
# DR法によるATE推定
from sklearn.linear_model import LinearRegression
# 結果変数の回帰モデルを作成
model_y = LinearRegression().fit(treated[['room_temp_cat', 'oven_condition']], treated['shape_quality'])
# DR推定量の計算
dr = (treated['shape_quality'] - model_y.predict(treated[['room_temp_cat', 'oven_condition']])) * weights / weights.sum() + model_y.predict(control[['room_temp_cat', 'oven_condition']]).mean()
ate_dr = dr.mean()
print(f'ATE by DR: {ate_dr}')ATE by DR: 87.88428209184154
製造プロセスの最適化に向けて
今回のブログでは、マッチング、IPTW法、DR法を用いたATE推定手法を紹介し、それぞれの手法が製パン工程の最適化にどのように役立つのかを示しました。
これらの手法は、製造プロセスの最適化だけでなく、品質管理や新製品の性能評価など、研究開発の様々な場面で活用できます。
しかし、これらの手法を適用する際には注意が必要です。
傾向スコアは、観測された共変量を考慮した上での処置を受ける確率を示すものであり、未観測の共変量については考慮できません。
したがって、未観測の共変量が存在し、それが原因変数と結果変数の両方に影響を及ぼす可能性がある場合、傾向スコアを用いた分析結果はバイアスを含む可能性があります。
以上の点を踏まえて、本記事の内容を参考に、皆様の研究や開発の現場でのデータ分析に活用していただければ幸いです。
処置効果の推定をもっとカスタマイズしたい方へ
私のブログでは特定のデータセットを使って、ビジネスですぐに活かせるコーディングの紹介を主目的としています。
そのためコーディングや成果を最大化するための使用方法はお伝えしますが理論的な部分は不足するかもしれません。もっと勉強されたい、スキル習得されたい方は、独自で勉強する方が良いと思います。
ただし、ライフスタイルのバランスや家族関係、自己実現のための時間の問題でなかなか踏み出せないのビジネスマンが多いと思います。
そこでお勧めなのは、勉強したい領域のみを自分で選んで、そこだけに特化して短時間で学べる「PyQ」オンラインスクールです。

今回であれば7days Python チャレンジ(7時間)と実務で役立つPython(12時間)、機械学習(62時間)を受講すれば習得できるはずです。
- 7days Python チャレンジ:7日間の無料体験でプログラミングの基礎を学ぶ
- 実務で役立つPython:実務で更にPythonを使っていきたい人のためのコース
- 機械学習:Pythonを使った機械学習をゼロから学びたい方のためのコース
月額制なので忙しくなれば途中退会も可能ですので、リスクは低いとおもいます。


