
試行錯誤から超効率最適化へ
前回の記事で、ベイズ最適化は機械学習の力を最大限活用した合理的な最適化手法で、従来の試行錯誤的なアプローチに比べ、ベイズ最適化なら以下のメリットがあると説明しました。
- 効率的なパラメータ空間の探索が可能
- 過去の評価結果を活用し、有望領域に自動誘導
- 繰り返し探索により、着実に最適解に収束
- 自動化で継続的な最適化を実現
本記事からは、ベイズ最適化を熱水銀硝の合成プロセスに応用して、非効率な試行錯誤から脱却でき、短期間で最適なプロセス条件を導き出せる具体的な手法を説明していきたいと思います。
適応的実験計画法によるシミュレーション

実際にベイズ最適化による熱水銀硝の合成プロセス最適化を、コーディングを交えて実例解説していきます。
ただし実際の実験は行えないため、適応的実験計画法によるシミュレーションを行います。
適応的実験計画法とは、最適化すべき対象に対し、効率的な情報収集と最適化を目指す手法です。
具体的には、あらかじめ実験条件と結果の関係性をモデリングしたデータセットを作成します。
そして適応的実験計画法に従い、ベイズ最適化によるパラメータ探索を行います。
これにより、実際に実験を行った時と同様のプロセスをシミュレートしていこうと思います。

熱水銀硝合成データセットの作成
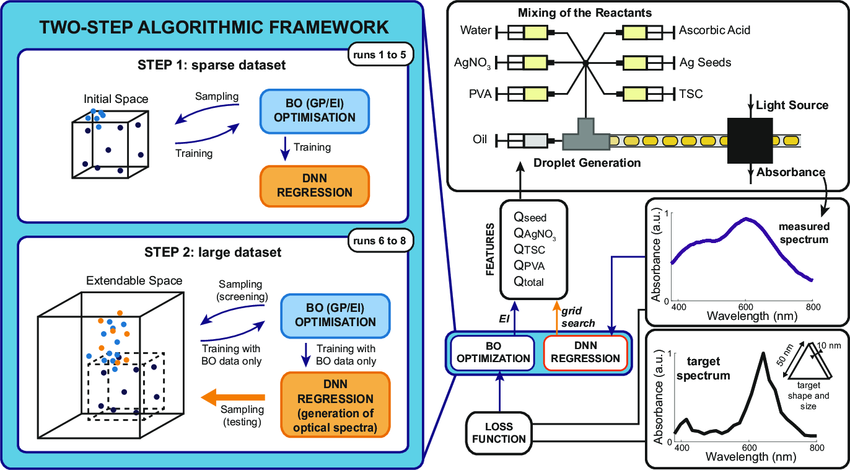
そこで今回は、熱水銀硝の合成プロセスのパラメータと損失値の関係を表すデータセットを作成しました。
Benchmarkingリポジトリから得たデータセットを基に、設計変数の中央値を計算し、それに対応する損失値との関係性をガウス過程回帰モデルで導出しています。
# 必要なライブラリのインポート
import numpy as np
import pandas as pd
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, WhiteKernel
# リポジトリデータセットの読み込み
df_raw = pd.read_csv("AgNP_dataset.csv")
# データの集計と中央値の計算
df = df_raw.groupby(["QAgNO3(%)","Qpva(%)","Qtsc(%)","Qseed(%)","Qtot(uL/min)"]).median().reset_index()[["QAgNO3(%)","Qpva(%)","Qtsc(%)","Qseed(%)","Qtot(uL/min)","loss"]]
# 設計変数(X)と目的変数(Y)の定義
obj_x=df[["QAgNO3(%)","Qpva(%)","Qtsc(%)","Qseed(%)","Qtot(uL/min)"]]
obj_y=df["loss"]
# カーネルの定義
obj_kernel_loss = RBF(length_scale=1, length_scale_bounds=(1e-12, 1e3)) + WhiteKernel(noise_level=1, noise_level_bounds=(1e-12, 1e5))
# ガウス過程回帰モデルのインスタンス化
obj_model_loss = GaussianProcessRegressor(kernel=obj_kernel_loss, normalize_y=True, alpha=1e-10, n_restarts_optimizer=3)
# モデルの適合
obj_model_loss.fit(obj_x,obj_y)
この作成したデータセットを使い、次回以降の記事で適応的実験計画法とベイズ最適化によるパラメータ探索のシミュレーションを行っていきます。
熱水銀硝合成プロセスの最適化を、コーディングを交えてわかりやすく解説していく予定です。

データセットの説明
設計変数(Design Variables):
- 銀硝酸の流量割合(%) (QAgNO3(%)):
5% から 42% までの連続値
- ポリビニルアルコール(PVA)の流量割合(%) (Qpva(%)):
10% から 40% までの5刻みの整数値
- 三ナトリウムシトラート(TSC)の流量割合(%) (Qtsc(%)):
1% から 30% までの2刻みの整数値
- 銀の流量割合(%) (Qseed(%)):
5% から 195% までの5刻みの整数値
- 総流量(µL/min) (Qtot(µL/min)):
200 µL/min から 950 µL/min までの50刻みの整数値
目的変数(Objective Variable):
- loss: 合成プロセスの損失を表す指標。
データセットのダウンロード
このデータセットを使って、ベイズ最適化の力でいかに合理的かつ効率的に最適なプロセスパラメータを見つけられるか、その実例を次回以降お届けします。
ベイズ統計と機械学習の知見を実装に活かす術を、ぜひ体感してみてください。
Two-step machine learning enables optimized nanoparticle synthesis | npj Computational Materials (nature.com)

データセット作成コーディングを理解したい方へ
今回のコーディングは機械学習とPythonプログラミング、特に統計・確率の理解が欠かせません。
scikit-learnを中心とした機械学習ライブラリの実装にも精通する必要があるので、本格的に学びたい方には、オンラインスクールをおすすめします。
TechAcademy(テックアカデミー)

選抜された現役エンジニアから学べるオンラインに特化したプログラミングスクールです。
データサイエンスコースでベイズ最適化の幅広い知識が身につきます。
無料体験に申込みしてみてもよいかもしれません。
一方で、ライフスタイルのバランスや家族関係、自己実現のための時間の問題でなかなか踏み出せないのビジネスマンには、勉強したい領域のみを自分で選んで、そこだけに特化して短時間で学べる「PyQ」オンラインスクールがお勧めです。

今回であれば7days Python チャレンジ(17時間)と機械学習(62時間)と統計分析コース(59時間)を受講すれば習得できるはずです。
- 7days Python チャレンジ:7日間の無料体験でプログラミングの基礎を学ぶ
- 統計分析:scipy.statsを使って、サンプリング、仮説検定ができるようになる
- 機械学習:機械学習をゼロから学びたい方のためのコース
月額制なので忙しくなれば途中退会も可能ですので、リスクは低いと思います。

