

データから因果関係を推定するベイジアンネットワークは、近年注目を集めている手法です。
しかし、機械学習だけに頼るのではなく、人間の過去の経験や知恵から構築された因果構造モデルの仮説を取り入れることが重要です。
CausalNexというPythonライブラリを使って、この人間とAIの協働による因果推論を実践してみましょう。
具体例として、職場の仕事満足度調査データを分析します。ベイジアンネットワークで因果構造をモデル化し、介入効果を推定することで、満足度に影響を与える要因を特定できます。


オープンソースソフトウェア(OSS)を使いこなす
CausalNexはオープンソースソフトウェア(OSS)です。
CausalNexは、因果関係の発見とシミュレーションのためのPythonライブラリで、因果推論のモデル構築やデータ解析を支援します。
ソースコードはGitHubで公開されています。
介入効果推定の強み ”CausalNex”で探ろう
従来の相関分析では、単に変数間の関係を見ているだけです。
しかし、介入効果推定では、特定の変数に介入した場合の影響を確率的に推定できます。
つまり、「もし◯◯の変数を変化させたら」という仮想的な介入を行い、他の変数がどう変化するかをシミュレートできるのです。
例えば、「研究開発適性が高い人に介入したら、満足度はどうなるか?」というケースを検証してみましょう。
本記事を読めば、CausalNexというPythonライブラリを使用して、ベイジアンネットワークを構築し、仕事満足度に影響を与える職業環境、能力、業務適正の因果構造を探り、事後確率を算出して、研究開発適性が高い人に介入した結果、満足度が高くなる確率が大きく上がることが分かります。
日本人は仕事に満足していますか?
具体例として、仕事満足度調査データを使います。
データはNTTDATAから引用させていただいております。このデータには、職業環境、能力、業務適正といった変数が含まれています。これらの要素が成果や仕事満足度にどのように影響するのかを因果推論していきましょう。表形式で変数とその日本語名をまとめたものを示します。
| 日本語名 | 変数 |
|---|---|
| 問題解決力 | problem_solving |
| 創造的思考力 | creative_thinking |
| 状況適応力 | situational_adaptability |
| 所属グループ | group_membership |
| 営業適性 | sales_aptitude |
| 研究開発適性 | research_dev_aptitude |
| 成果 | performance |
| 満足度 | satisfaction |
この変数を元に我々が調査データから導き出したい仮説を立てましょう。以下の仮説が考えられます:
- 問題解決力、創造的思考力、状況適応力が高い従業員は、成果と満足度が高い。
- 所属グループが良好な従業員は、成果と満足度が高い
- 問題解決力、創造的思考力、状況適応力が高い従業員は、営業適性が高い
- 問題解決力、創造的思考力、状況適応力が高い従業員は、研究開発適性が高い
- 営業適正や研究開発適性が高い従業員は、成果と満足度が高い
これらの仮説をベースに、因果構造を推測していきます。

ステップ1: データの準備
まずは、仕事満足度調査データを準備します。今回は日本語のカラム名を英語に変換しています。
import pandas as pd
# 仕事満足度調査データを読み込む
data = pd.read_csv('仕事満足度調査データ.csv', encoding='shift-jis')
# 変数のカラム名を英語に変更するマッピング
variable_mapping = {
'問題解決力': 'problem_solving',
'創造的思考力': 'creative_thinking',
'状況適応力': 'situational_adaptability',
'所属グループ': 'group_membership',
'営業適性': 'sales_aptitude',
'研究開発適性': 'research_dev_aptitude',
'成果': 'performance',
'満足度': 'satisfaction',
}
# カラム名を変更
data.rename(columns=variable_mapping, inplace=True)
# 変更後のカラム名を確認
print(data.columns)
# データの先頭部分を確認
print(data.head())今回のデータはカテゴリカルなデータになっているので、ベイジアンネットワークを構築するために、カテゴリカルなデータを数値データに変換する必要があります。
LabelEncoderを使って、カテゴリカルなデータを整数にエンコードします。具体的には、各カテゴリに対して一意な整数を割り当てることで、カテゴリカルデータを数値化します。
from sklearn.preprocessing import LabelEncoder
import numpy as np
# カテゴリカルなデータの抽出
struct_data = data.copy()
non_numeric_columns = list(struct_data.select_dtypes(exclude=[np.number]).columns)
# LabelEncoderをインスタンス化
le = LabelEncoder()
# 各非数値カラムに対してLabelEncoderを適用する
for col in non_numeric_columns:
struct_data[col] = le.fit_transform(struct_data[col])
struct_data.head(5)ステップ2: モデルの定義
CausalNexを使用して、因果構造モデルを定義します。これには、ノード(変数)とエッジ(因果関係)を指定します。
from causalnex.structure.notears import from_pandas
from causalnex.structure import StructureModel
# モデルの学習や確率推論の前に、CausalNexで利用できるデータ形式に変換する
sm = from_pandas(struct_data)
# ノード(変数)とエッジ(因果関係)を指定する
sm = StructureModel()
sm.add_edges_from([
('problem_solving', 'sales_aptitude'),
('creative_thinking', 'sales_aptitude'),
('situational_adaptability', 'sales_aptitude'),
('problem_solving', 'research_dev_aptitude'),
('creative_thinking', 'research_dev_aptitude'),
('situational_adaptability', 'research_dev_aptitude'),
('group_membership', 'performance'),
('sales_aptitude', 'performance'),
('research_dev_aptitude', 'performance'),
('group_membership', 'satisfaction'),
('sales_aptitude', 'satisfaction'),
('research_dev_aptitude', 'satisfaction'),
])ステップ3: モデルの可視化
モデルを可視化して因果関係を理解しやすくします。ここで正しく仮説通りにネットワーク構造が描画できているか確認して、間違っている場合にはadd関数やremove関数で修正してください。
import matplotlib.pyplot as plt
import networkx as nx
# ノードとエッジのスタイル設定
node_size = 4000
arrowsize = 20
alpha = 0.6
edge_color = 'b'
# プロットの準備
plt.figure(figsize=(18, 10))
pos = nx.spring_layout(sm, k=60)
# エッジの幅を設定(重みによって変化)
edge_width = [1 for (u, v) in sm.edges()]
# ノードのラベルを描画
nx.draw_networkx_labels(sm, pos, font_size=16, font_family="Yu Gothic", font_weight="bold")
# ネットワークを描画
nx.draw_networkx_edges(sm, pos, width=edge_width, edge_color=edge_color, alpha=alpha)
nx.draw_networkx_nodes(sm, pos, node_size=node_size, alpha=alpha)
# グラフを表示
plt.show()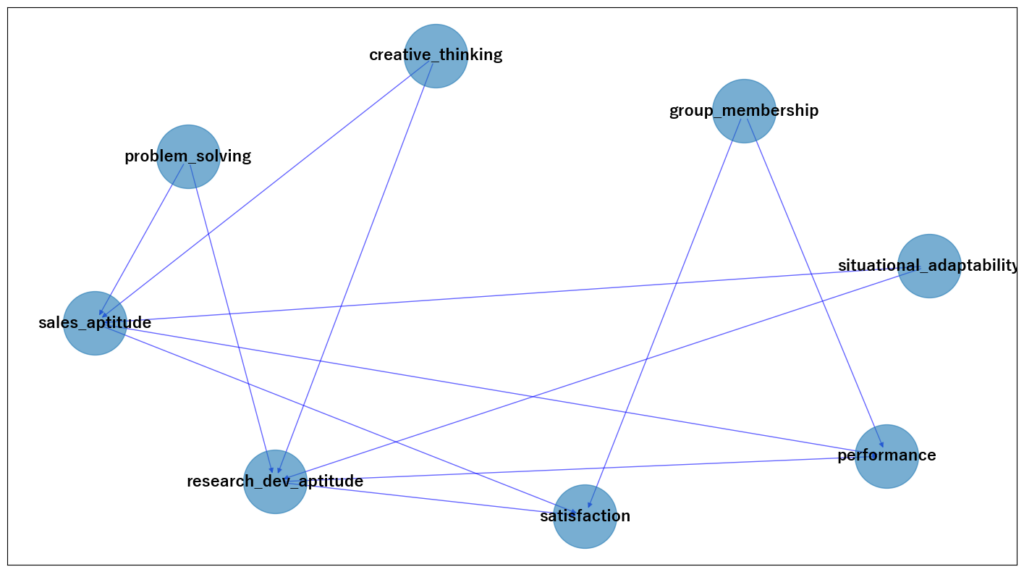
ステップ4: 事前確率の確認
CausalNexを使ってベイジアンネットワークの事前確率を確認します。事前確率(Prior Probability)は、ベイジアンネットワークにおいて、特定の変数が特定の状態(値)を取る確率を示すものです。これは、他の変数に関する情報が与えられていない状態での、その変数の確率です。
from causalnex.network import BayesianNetwork
from sklearn.model_selection import train_test_split
# ベイジアンネットワークを構築
bn = BayesianNetwork(sm)
# ノードの状態を学習する
bn = bn.fit_node_states(struct_data)
# データにベイジアンネットワークを適合させて条件付き確率分布を学習
bn = bn.fit_cpds(struct_data)
# InferenceEngineを作成
from causalnex.inference import InferenceEngine
ie = InferenceEngine(bn)
# 全てのノードの条件付き確率分布を一覧表示
for node in bn.nodes:
cpd = bn.cpds[node]
print(f"CPD for {node}:\n{cpd}")例えば、成果(performance)が0(高い成果)と1(低い成果)のどちらかを取る確率を事前確率として示します。以下は、成果の事前確率の具体的な値です。
performance(成果)の事前確率:
- 成果が0の場合の確率: 0.606667
- 成果が1の場合の確率: 0.393333
この事前確率は、変数performanceが特定の値を取る確率を示しています。例えば、成果が0である確率が0.606667、成果が1である確率が0.393333ということです。
ステップ5: 事後(介入後)確率の確認
それでは研究開発職に適性がある人が満足度が高いかどうかの検証してみましょう。それは事後確率を算出することで検証することができます。事後確率(Posterior Probability)は、ベイジアンネットワークにおいて、ある条件(例えば、特定の変数に対する介入)が与えられた後の変数の確率を示すものです。つまり、特定の条件下での変数の確率を表します。
from causalnex.network import BayesianNetwork
from causalnex.inference import InferenceEngine
# InferenceEngineを作成
ie = InferenceEngine(bn)
# 現在の状態を表示
print("satisfaction:", ie.query()["satisfaction"])
# 'research_dev_aptitude'ノードに介入
ie.do_intervention("research_dev_aptitude", {1: 0.0, 0: 1.0})
# 介入後の状態を表示
print("介入後のsatisfaction:", ie.query()["satisfaction"])
以下に、satisfaction(満足度)の事後確率(介入前)と介入後の結果を表にまとめます。
| 満足度 | 事後確率(介入前) | 事後確率(介入後) |
|---|---|---|
| 0 | 0.36373460012059955 | 0.21988262670499634 |
| 1 | 0.6362653998794003 | 0.7801173732950037 |
研究開発適性が高い人々(research_dev_aptitudeが1、高い適性)を介入させた後の満足度の確率を比較すると、研究開発適性が高い人々に介入した結果、満足度が高い確率(1)が0.636から0.780に増加し、満足度が低い確率(0)が0.364から0.220に減少していることがわかります。
この結果から、研究開発職に適性がある人々に介入することで、満足度が高まる可能性があることが示唆されています。介入後の事後確率を見ることで、特定の条件が変数に与える影響や因果関係をより理解することができます。
このように、人間が実際に介入実験を行うことで、ベイジアンネットワークで推定された因果構造を検証し、適宜モデルを修正することができます。人間の知見とデータ分析を組み合わせることで、より妥当な因果関係を導き出せるのです。
人間の知見とAIの融合
ベイジアンネットワークを使用した因果推論は、仕事満足度調査データの解析において興味深い結果をもたらしました。
これらのデータから得られた因果関係の仮説をベースに、モデルの構築から事後確率の推定までを行いました。
その結果、研究開発職に適性がある人が、満足度に与える影響が高いことが示されました。
因果推論においては、機械学習技術と人間の専門知識が融合することが重要です。
ベイジアンネットワークを使った解析は強力なツールでありながらも、データだけでは理解できない部分も存在します。
そのため、専門家の洞察とAIの能力を組み合わせることで、より深い洞察が得られることが期待されます。
最終的に、ベイジアンネットワークは因果関係の理解と予測において重要な役割を果たしますが、人間とAIの協働が成功の鍵となります。因果推論の新たな地平を切り拓くためには、推定されたモデルの検証と改善を継続的に行い、データ駆動の意思決定による効果的な意思決定を支援していくことが不可欠です。
人間の創造性とAIの計算能力を組み合わせ、因果推論の可能性を探求する旅はまだ始まったばかりです。これからもこの分野の進展に注目し、新たな発見と知見を共有していきましょう。

処置効果の推定をもっとカスタマイズしたい方へ
私のブログでは特定のデータセットを使って、ビジネスですぐに活かせるコーディングの紹介を主目的としています。
そのためコーディングや成果を最大化するための使用方法はお伝えしますが理論的な部分は不足するかもしれません。もっと勉強されたい、スキル習得されたい方は、独自で勉強する方が良いと思います。
ただし、ライフスタイルのバランスや家族関係、自己実現のための時間の問題でなかなか踏み出せないのビジネスマンが多いと思います。
そこでお勧めなのは、勉強したい領域のみを自分で選んで、そこだけに特化して短時間で学べる『Schoo(スクー)』ライブ動画コミュニティと「PyQ」オンラインスクールです。
ベイジアンネットを理論的に学ぶなら『Schoo(スクー)』ライブ動画コミュニティ
【エンジニアのためのベイズ統計学】第7回エンジニアのためのベイズ統計学-ベイジアン・ネットによる「人工知能」を受講すれば、ベイズ統計学の基礎概念からベイジアンネットまでを、事例を交えながら学べます。
今なら7日間無料登録やってるみたいなのでお得ですね‼
Pythonコーディングを効率的に学びたいなら「PyQ」オンラインスクールです

今回であれば7days Python チャレンジ(7時間)と実務で役立つPython(12時間)、機械学習(62時間)を受講すれば習得できるはずです。
- 7days Python チャレンジ:7日間の無料体験でプログラミングの基礎を学ぶ
- 実務で役立つPython:実務で更にPythonを使っていきたい人のためのコース
- 機械学習:Pythonを使った機械学習をゼロから学びたい方のためのコース
月額制なので忙しくなれば途中退会も可能ですので、リスクは低いとおもいます。


